The natural-language instructions that steer agents often get less tooling than a config file. That felt wrong to me. If a SKILL.md tells an agent to read a file that is missing, or recover from an error it never describes, I want to know before the agent runs.
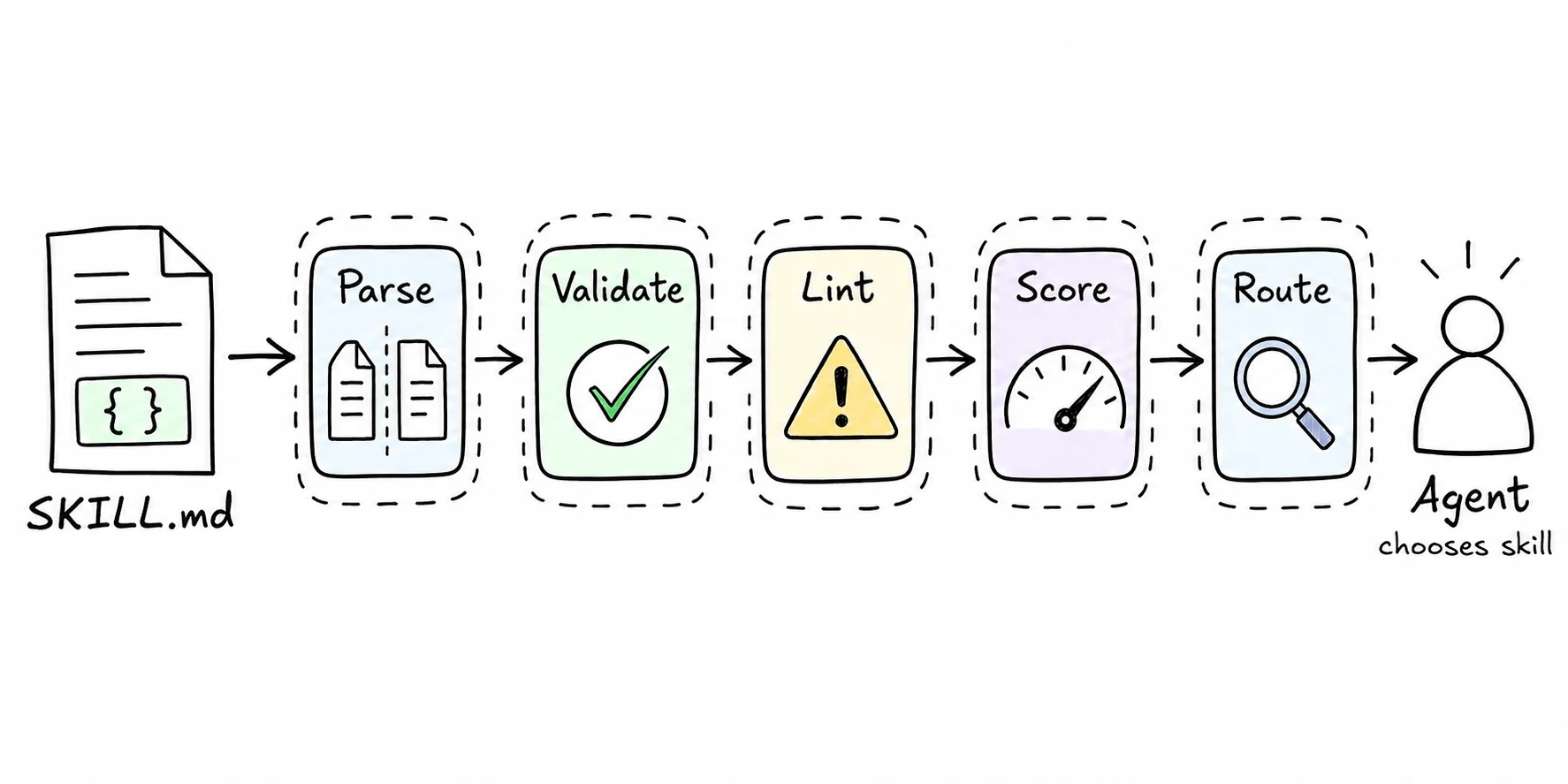
So I built skill-tools, a small TypeScript toolchain for SKILL.md files. The pipeline is intentionally deterministic:
- Parse: split frontmatter from Markdown, validate required fields, and resolve referenced files.
- Validate: check the structure expected by the skill spec.
- Lint: flag risky patterns like hardcoded local paths, vague descriptions, and missing error handling.
- Score: make quality visible across description, clarity, compliance, disclosure, and security.
- Route: use BM25 to pick relevant skills from name, description, and selected body context.
The best bug it catches is also the least dramatic one: a skill says "read references/foo.md," but that file is not shipped with the skill. A human might miss it in review. An agent will usually try the path, fail, and waste turns recovering. The parser catches it immediately.
skill-tools validate ./skills/*
error missing-reference references/foo.md
warn missing-error-handling
info vague-description: "manage"I chose BM25 for routing because it is boring and inspectable. If a query routes to the wrong skill, I can look at the terms and fix the description. That is harder with a vector that only says "close enough." For high-risk routing, I still like a reranker after retrieval. BM25 is the cheap first pass, not a religion.
The larger point is simple: agent instructions deserve the same basic treatment we give code. Parse them. Check them. Fail CI on the things that can break a run. Do not wait for the model to discover the missing file at runtime.
GitHub / Docs / Try in browser