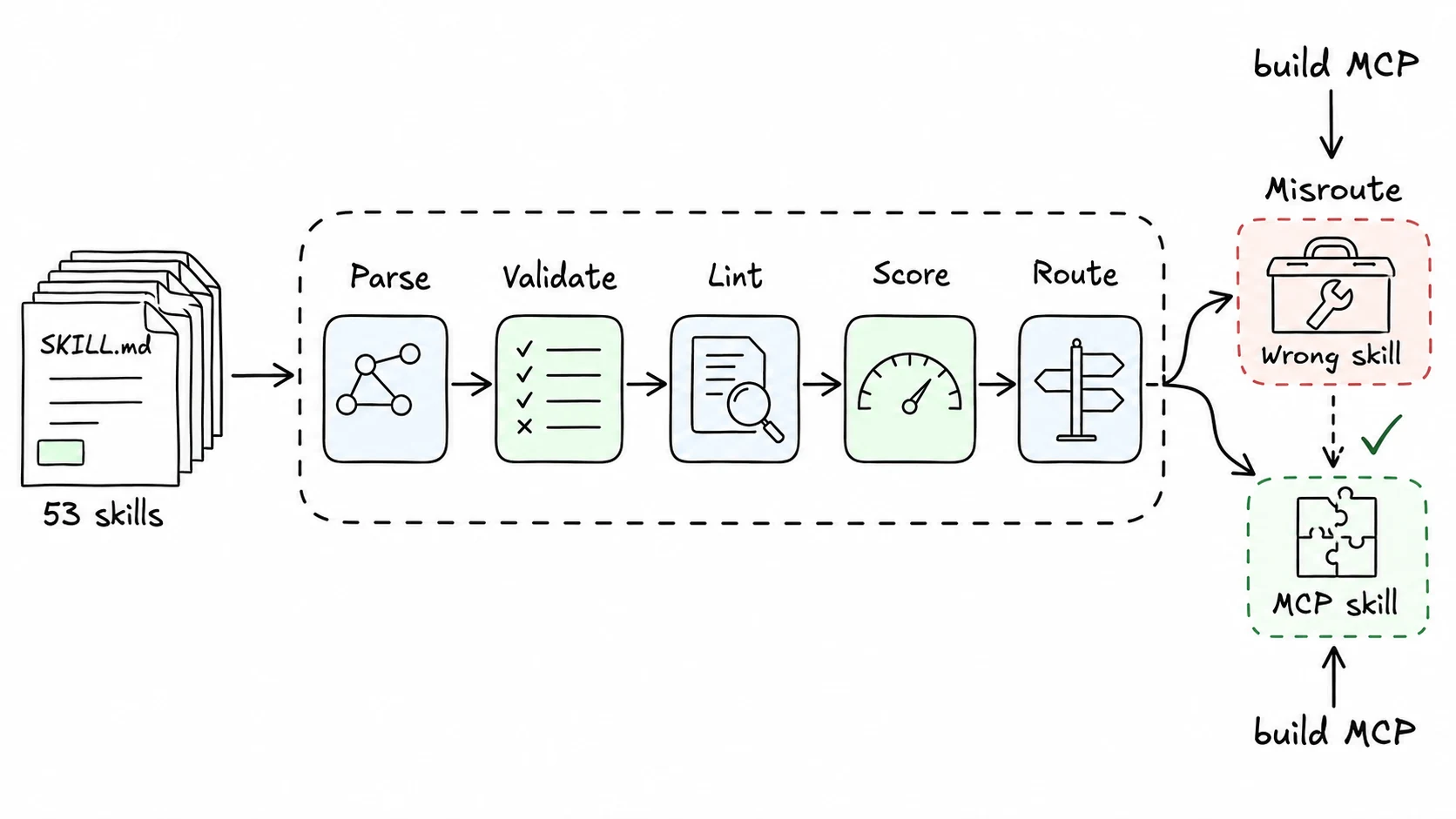
I ran 53 SKILL.md files through skill-tools. The biggest lesson was not that some files were messy. It was that small instruction defects turn into agent failures very quickly.
The first failure class was missing references. A skill can mention scripts/rotate_pdf.py or references/citations.md, but if that file is not actually included, the agent only finds out while executing the skill. My parser catches that at build time.
The second class was recovery. Many skills explain the happy path but never say what to do when a command fails, a browser page changes, or a required dependency is missing. That is exactly when agents loop. Good skills give the agent a next move: retry once, inspect logs, ask the user, or stop.
The third class was discoverability. I tested routing with plain English queries. One query, "build an MCP server," matched a Figma-related skill because the words "MCP server" appeared there, even though the intended skill was the one for building MCP servers. BM25 did what BM25 does: it matched terms, not intent.
That misroute changed how I think about skill descriptions. A good description is not a summary. It is routing metadata. It should include trigger phrases a user would actually type, and it should avoid broad verbs like "manage" when a narrower verb exists.
The fixes were practical:
- Fail parsing when referenced files are missing.
- Warn when there is no error-handling section or recovery guidance.
- Score descriptions for specificity and trigger phrases.
- Enrich routing with headings and code terms from the body, not only the frontmatter.
I do not treat these scores as a moral judgment on a skill. They are a debugging tool. They tell me where the instruction is likely to fail before a model spends tokens finding out.