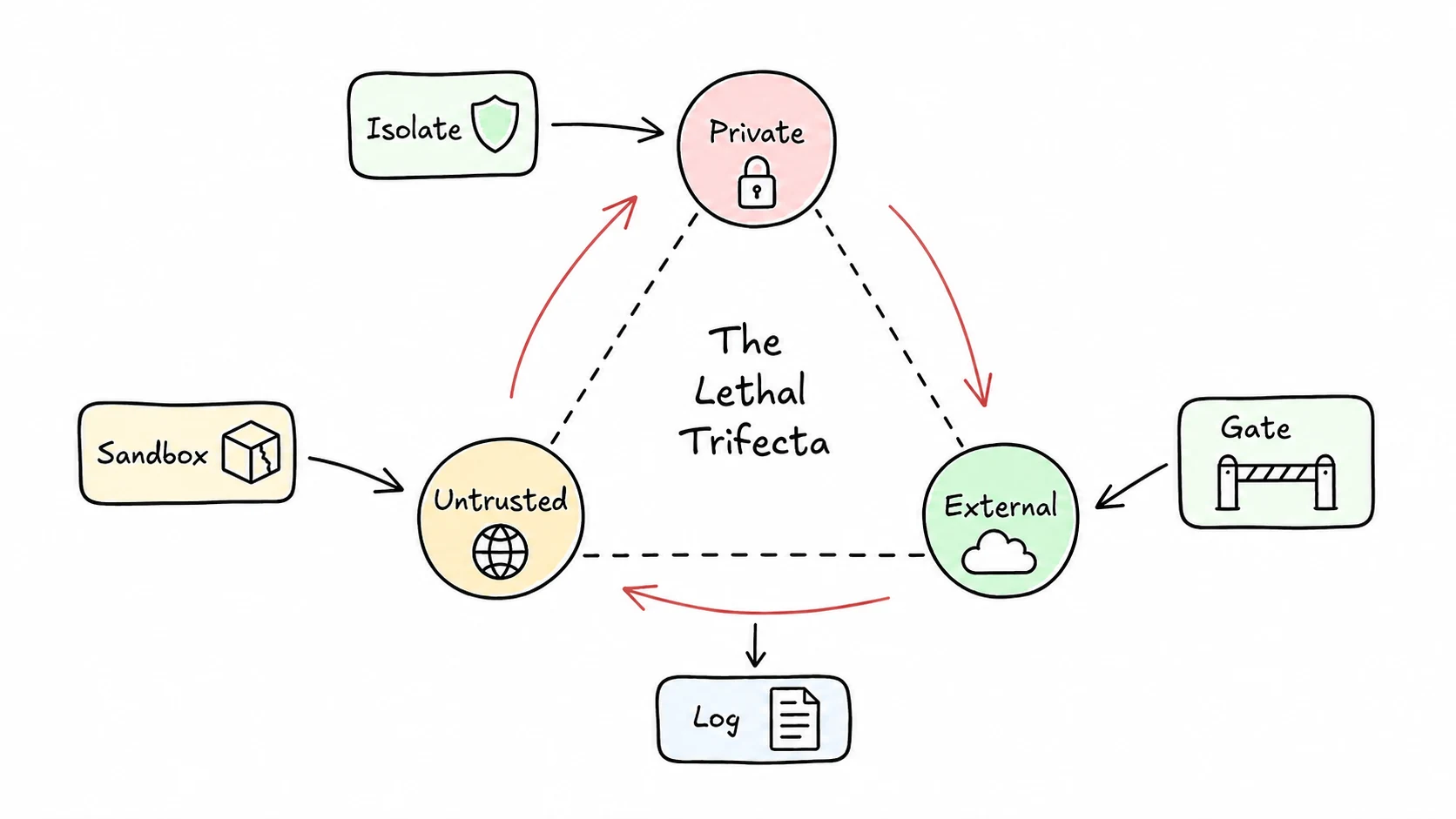
Simon Willison's lethal trifecta is the cleanest threat model I know for agents: private data access, untrusted content, and a way to communicate outward. Put all three together, and prompt injection becomes an exfiltration path.
The GitHub MCP exploit demonstrated the shape of the problem. A malicious public issue instructed an agent to use the developer's GitHub access to inspect private data, then leak it through a public pull request. The model did not need a software vulnerability. It needed too much authority and too little separation.
That maps directly to browser agents. The page is untrusted content. The logged-in session may have private data. A form submit, navigation, file upload, or message send can move data outward. You cannot prompt your way out of that. You need controls at the boundary where the agent acts.
In BAP, I think about the controls this way:
- Isolate credentials. The model should not receive raw passwords, tokens, or cookies directly. Browser session state stays in the browser context.
- Restrict scope. One task gets the narrowest browser context and network scope that can do the job.
- Gate external actions. Submitting forms, sending messages, changing domains, downloading files, and spending money should be explicit actions with policy around them.
- Log the trail. You need the page, selector, action, and result for every meaningful step.
None of this makes prompt injection disappear. The point is to make a successful injection less useful. If a page convinces the model to send private data somewhere, the send still has to pass a gate. If a run goes wrong, the log should show the pivot.
My default rule is: anything that leaves the current trust boundary needs a second look. That can be a human confirmation, a policy check, or a narrower tool that cannot exfiltrate by design. The right answer depends on the workflow, but "the model will know better" is not one of the options.
Source framing: Simon Willison on the lethal trifecta.