A CSS selector answers "where is this element in the document?" A semantic selector answers "what is this element?" For browser agents, that difference is the difference between a workflow that survives a redesign and one that clicks the wrong button.
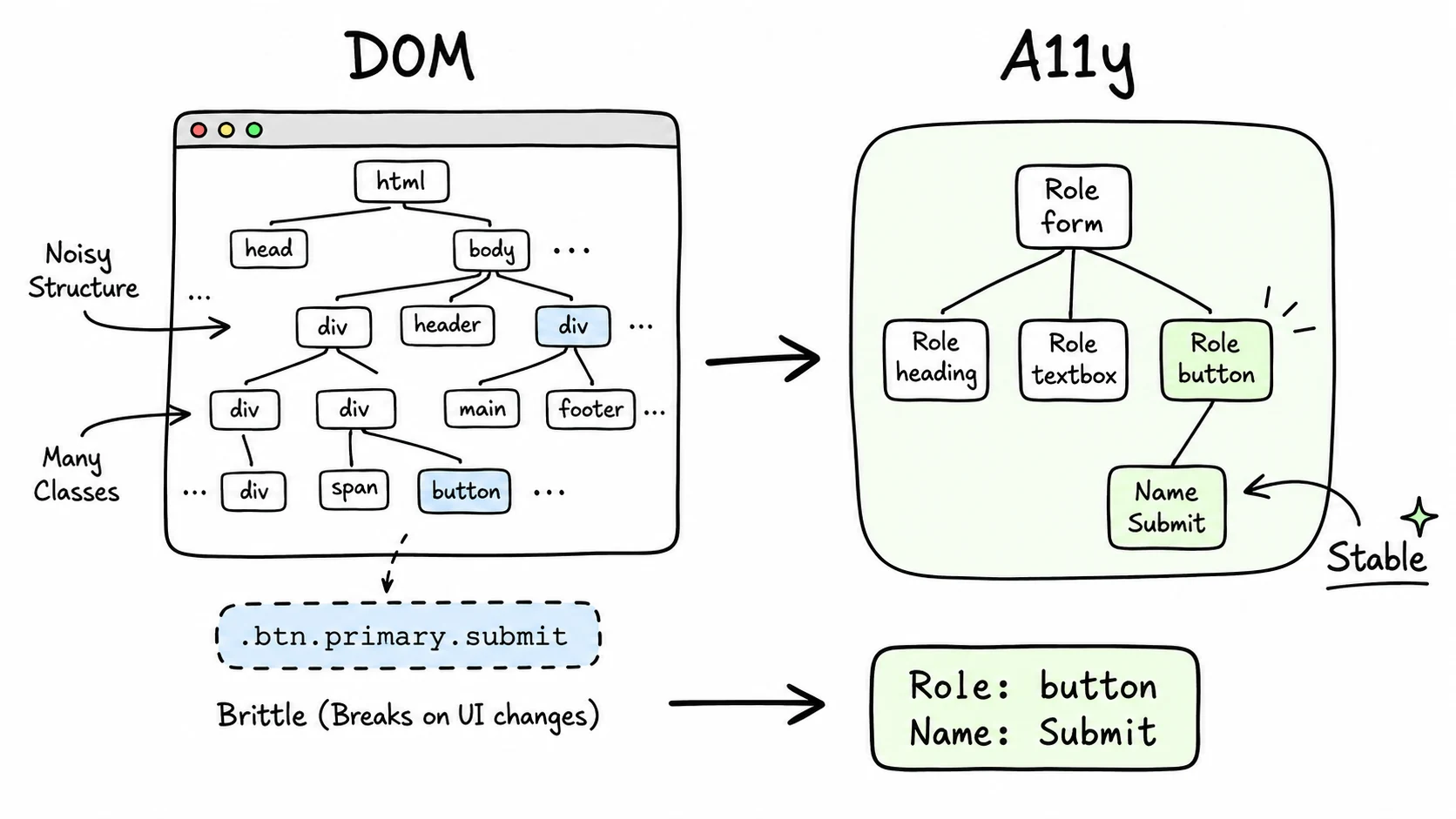
Take this button:
<button class="btn-primary mt-4">Submit Order</button>The DOM carries class names, wrapper nodes, and layout detail. The accessibility tree keeps the part the agent needs:
{ "role": "button", "name": "Submit Order" }That is why Playwright recommends role and label locators before CSS selectors. It is also why I built BAP around the same hierarchy. If the class changes from btn-primary to btn-action, the role and name stay the same. If the button moves from the left column to the right column, the role and name stay the same.
The hierarchy I use is straightforward:
- Role plus accessible name, like button "Submit Order".
- Form label, like textbox labeled "Email".
- Visible text when role and label are not enough.
data-testidwhen the app provides one.- CSS only as the last resort.
This also makes websites better for people. Good labels, native controls, keyboard focus, and landmark roles help screen readers and agents for the same reason: both consume the page through structure, not vibes.
I do not think semantic selectors solve every browser automation problem. Bad markup still hurts. Duplicate labels still require disambiguation. But starting from meaning gives the agent a much better default than starting from pixels or class names.