The failure mode I kept seeing was not that Claude could not write code. It was that the session had no process. It would make a large diff, skip the boring checks, and hand me a review problem.
I built staff-engineer to add a small amount of engineering discipline around AI coding work. The plugin does not make the model smarter. It gives the session a harness.
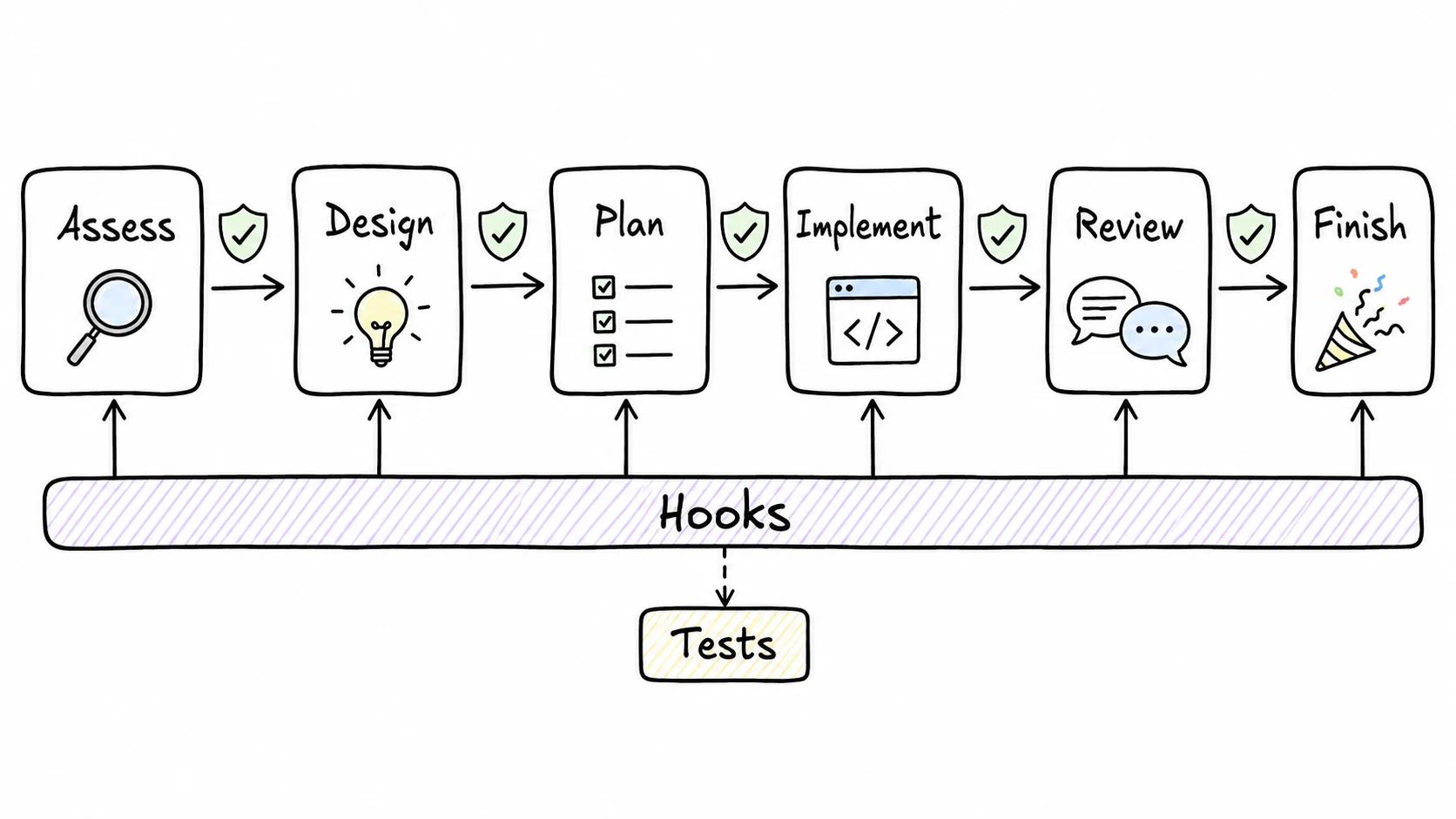
The workflow is simple:
- Assess: decide whether the task is a typo, a small change, a standard feature, or something risky.
- Design: write down the approach before editing high-impact code.
- Plan: split the work into reviewable tasks.
- Implement: make the change, usually with tests close to the diff.
- Review: run quality, spec, and security checks where they apply.
- Finish: summarize, test, commit, and prepare the PR when allowed.
The useful part is that hooks enforce the moments models tend to skip. A pre-push hook can block direct pushes to protected branches. A pre-commit hook can flag missing tests. A post-edit hook can warn when the agent touches files outside the plan.
This matters because a prompt like "always run tests" is a reminder. A hook is a gate. The agent can forget the reminder. It has to deal with the gate.
I also added trust levels. Local, reversible actions can run automatically. Actions that affect other people, like pushing a branch or marking a PR ready, ask first. Irreversible or high-blast-radius actions stop and produce a plan. That split has saved me more than any single prompt tweak.
The plugin is opinionated because my workflow is opinionated. Small diffs, visible checks, and explicit handoffs beat giant autonomous commits. I still want the agent to move fast. I just want the path to have rails.
Package: @pyyush/staff-engineer.