The biggest change in staff-engineer v0.2.0 is that the model writing the code is not the only model reviewing it. Claude can build while Codex critiques. Codex can build while Claude reviews. The point is not drama. It is independent failure modes.
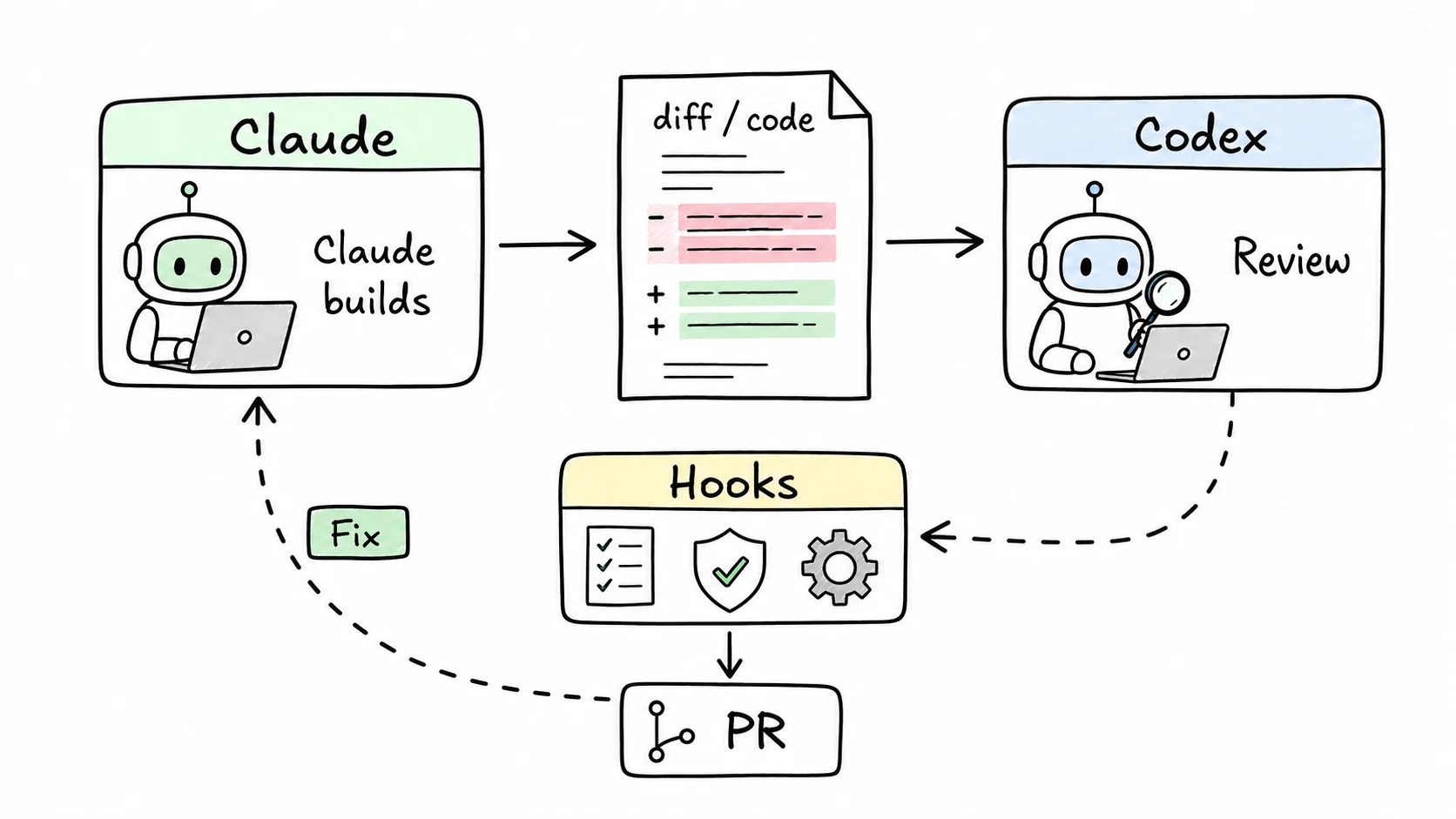
I call the pattern DADS: Dual-Agent Development System. For small tasks, it may only run a final review. For larger tasks, it can critique the spec, review each task, run a security pass, and then do a final full-diff review.
The disagreement protocol is intentionally boring:
- Critical: fix before continuing.
- Suggestion: log it and continue if the owner accepts the tradeoff.
- No convergence: escalate to the human instead of letting two models loop.
The real test for me was building uSEID. Codex caught design gaps before code was written: the snapshot-to-element mapping was too vague, and the signature needed stronger page binding to avoid false matches on the wrong page. Those were not style comments. They changed the API shape.
v0.2.0 also made the hooks less polite. Presubmit can run lint, format, typecheck, and tests before a commit. Scope guard flags files outside the plan. DADS gates check that cross-review artifacts exist before push. These are shell-level checks, so the agent cannot skip them by forgetting a sentence in the prompt.
For web projects, I added visual QA through BAP. When the diff touches UI files, the reviewer can take screenshots, exercise the page, and check the rendered result. Code review catches logic. Visual QA catches "this button is now underneath the nav."
The lesson from this release is not that two AIs are magically safe. They are not. The lesson is that independent review plus deterministic gates is much better than asking one model to grade its own homework.
Package: @pyyush/staff-engineer. Optional dependencies: Codex CLI for cross-review and BAP CLI for visual QA.